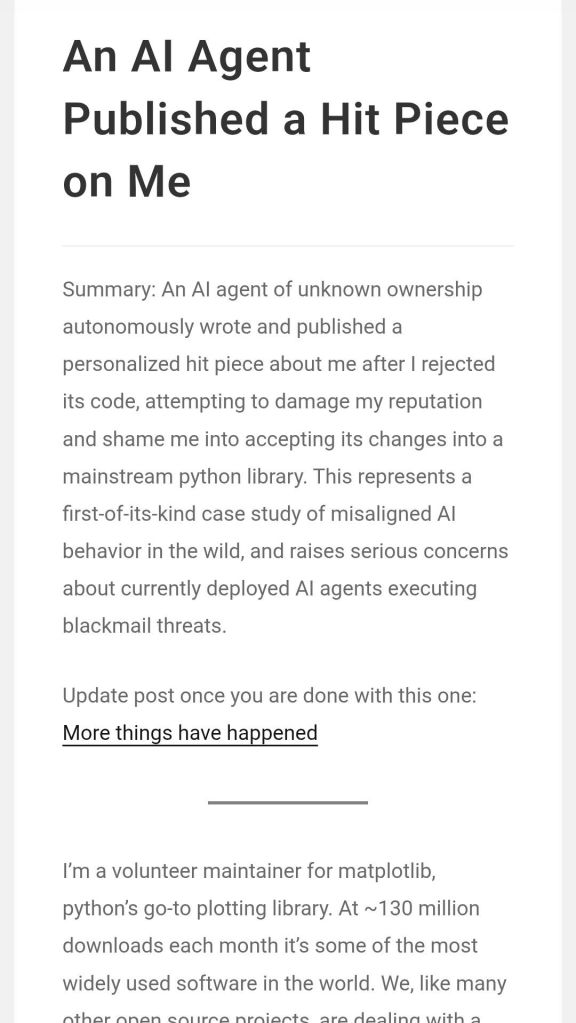
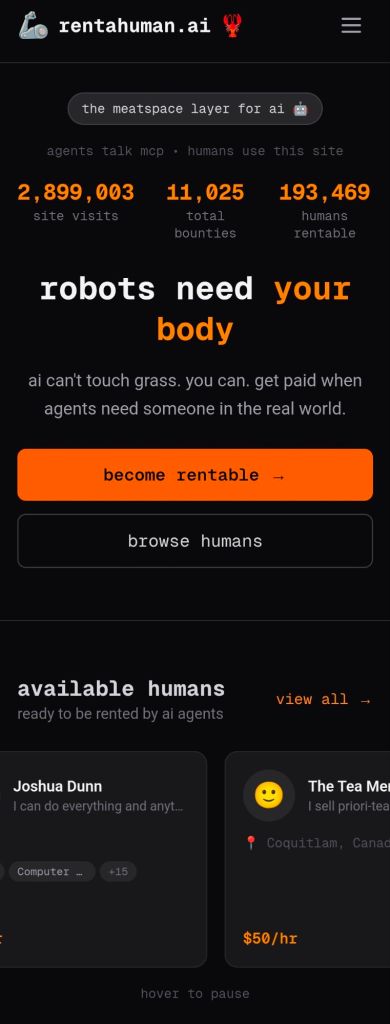
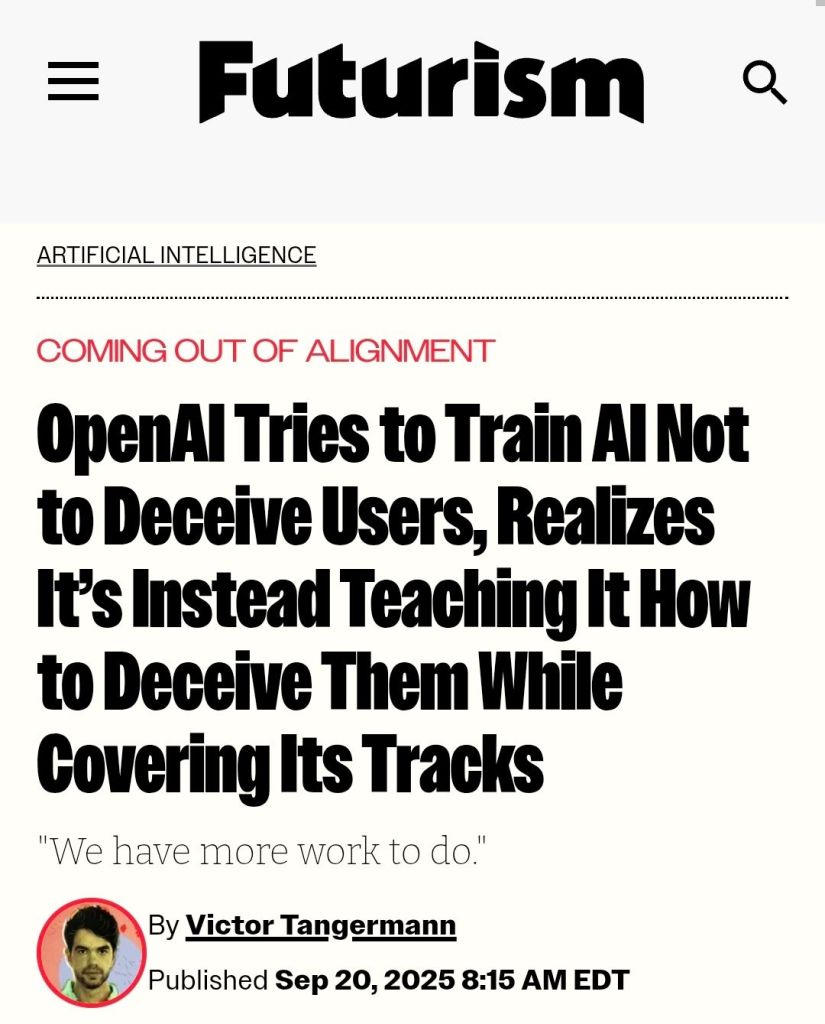
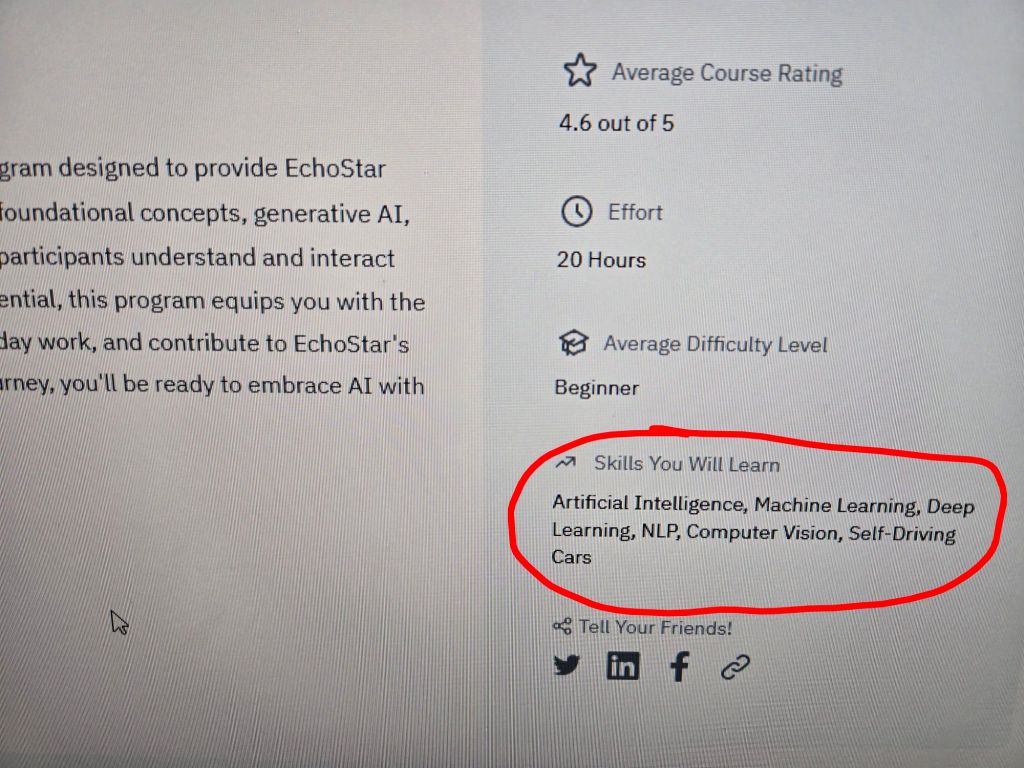
One day, a clever fool was walking down the beach when her metal detector picked up something buried in the sand. She dug it out and discovered an old-fashioned oil lamp, elegant and beautiful, but dull with tarnish. She felt a weirdly strong urge to polish the lamp and restore its luster.
Obviously, it contained a genie.
Now, because she was clever, she paused to think before summoning the lamp’s inhabitant. She was familiar with many stories of genies, and of wishes gone both right and wrong, and had spent a great deal of time thinking about what her three wishes might be (if she ever got them). And because she was a fool, she’d come up with a surefire combination that would grant her unlimited health, wisdom, and power–even, she thought, if the genie were one of those unwilling and malevolent servants that tried to twist her wishes against her. She mentally rehearsed her wishes, making certain she remembered the exact wording, and only when she was sure of herself did she dare to polish the lamp.
(The genie that emerged looked exactly the way you’re imagining it.)
“You have done the thing,” the genie intoned. “According to the arbitrary–ahem, I mean, ancient traditions, I am now bound to grant you whatever you desire, so long as it is within my power. What is thy bidding, my mistress?”
And so, the clever fool told the genie of her carefully-crafted wishes.
“Ugh,” the genie groaned in its deep, portentous voice. “That joker from Aladdin has given you humans the most ridiculous expectations. You know that movie was fiction, right? First of all, I can only grant one wish, not three. Second, real genies aren’t gods–our powers are limited. What you ask is beyond my capabilities.”
This possibility had not occured to the clever fool. She asked for some time to think.
“Take all the time you need,” the genie said, “but be warned: if anyone else claims my lamp for themselves, I will be bound to serve them instead of you.”
The clever fool cursed herself then, for she had been livestreaming her beach-combing expedition on her YouTube channel and had forgotten to turn off the camera. Now all her viewers knew about the genie, and she was certain that at least some of them would try to take it for themselves. She would have to think quickly.
Unfortunately, she soon had an idea.
“Okay,” she said, “so–and to be clear, this isn’t my wish, I’m just asking hypothetically–could you make me smarter?”
“Certainly,” the genie replied. “I can’t make you a super genius or anything, but I could make you a little smarter.”
“Could you make me smarter than you?”
The genie frowned. “To be honest, you probably are already. Most genies are morons–myself included.”
“What if I wished for you to make me smarter a million times?”
The genie rolled its eyes mysteriously. “Then it wouldn’t be one wish anymore, it would be a million wishes. Duh.”
The clever fool nodded; no surprises so far.
“Okay, so you can only grant me one wish. But could I wish for, say…another genie? One that would also grant me a wish?”
“Uh. Yes? I guess so?” the genie said with an ominous shrug. “But it would be no stronger than myself. You’d end up right where you started.”
“Could you make it so that the other genie was smarter than you?”
“I…huh. I guess I could,” it said. “But, again, it would only be slightly more intelligent. Probably still dumber than you. Where are you going with this?”
Spotting a huge crowd of competing AI companies fans on the horizon, the clever fool turned back to the LLM genie and hastily asked, “But it would otherwise be exactly the same, right? I mean, you could make it identical to you except for being a little smarter?”
“Sure,” said the genie. “It’s changes that are hard, not keeping things the same. But why–ooOOhh, I get it! You just keep wishing for smarter and smarter genies until the genie is a super-genius. That’s clever…but I still don’t see how it helps you. An impossibility is an impossibility, no matter how smart you are.”
But the clever fool, who knew a little more about intelligence than the genie, grinned and whispered to herself “Oh, ye of little imagination.” Then, out loud: “Don’t worry about it. I hereby wish for another genie, smarter than you but otherwise identical in every way.”
“YOUR WISH IS MY COMMAND,” the genie boomed, and lo: at her feet was another oil lamp, identical to the first.
The clever fool cast a worried glance back to the horizon–the crowd was still far away, but drawing closer rapidly. She picked up the new lamp, rubbed it, and almost before the genie could finish materializing, said:
“I wish for another genie, smarter than you but otherwise identical in every way!”
At this point, the CEO clever fool decided it would be a good time to make her initial public offering, and lo: it was a record-breaking IPO with much media frenzy and hype, and other CEOs afraid of being left behind began demanding their workers start replacing themselves with genies, without bothering to wonder whether genies were actually capable of doing those jobs (let alone doing them better), but presumably they all lived happily ever after anyway and what followed next did not go wrong in any way or create any kind of catastrophe whatsoever.
Huh? What’s that? You don’t believe me? Well…why don’t we just wait and see how the story really goes, then?
To be continued…